起源是这样一道题目:
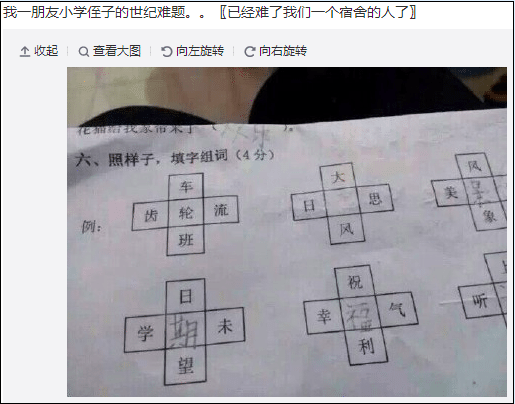
于是想到通过word dict来算一下:
先去下载了中文词库:
git clone git@github.com:ling0322/webdict.git
然后去掉词频信息:
awk ‘{ if (length($1)==2) print $1}’ webdict_with_freq.txt >webdict.txt先按照出现位置来正则过滤候选集,并且去掉大/日/风/思四个字:
grep ‘^大.*’ webdict.txt| sed ‘s/大//g’ >da.txtgrep '^日.*' webdict.txt| sed 's/日//g' >ri.txt
grep '.*风$' webdict.txt| sed 's/风//g' >feng.txt
grep '.*思$' webdict.txt| sed 's/思//g' >si.txt
之后的事情就很有意思了,每次join两个文件,因为大/日/风/思四个字是没有交集的,所以结果就是要求的字:
comm -12 <(sort da.txt|uniq ) <(sort ri.txt|uniq ) >da_ri.txtcomm -12 <(sort feng.txt|uniq ) <(sort da_ri.txt|uniq ) >da_ri_feng.txt
comm -12 <(sort si.txt|uniq ) <(sort da_ri_feng.txt|uniq ) >da_ri_feng_si.txt
最后的凶手答案只有一个:
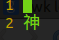
谢谢观看~。
参考文献:
[1] LINUX Shell 下求两个文件交集和差集的办法, http://blog.csdn.net/autofei/article/details/6579320
PREVIOUSdjango重定向的参数传递
NEXT关于java编码规范